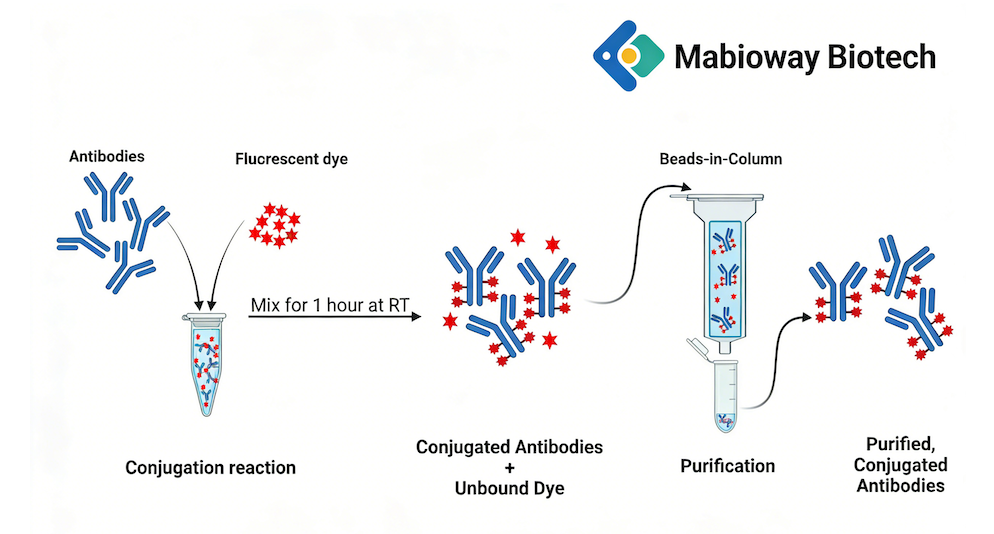
蛋白质的三维结构对于理解其生物学功能和候选药物的设计至关重要。近年来,结构生物学取得了巨大进展,大量新的大分子结构已通过X射线晶体学、核磁共振和低温电子显微镜等实验方法确定。尽管取得了令人瞩目的进展,但获取每种目标蛋白质的结构仍然普遍困难且耗时。因此,计算方法应运而生,成为实验方法的有力替代和补充。
同源性建模(也称为比较建模)是迄今为止预测蛋白质结构最可靠、最成熟的计算方法。该方法首先识别一个或多个相关同源蛋白质的实验性三维结构,并将其用作模板,在此基础上,根据目标蛋白质的氨基酸序列构建其原子分辨率模型。研究表明,蛋白质的三维结构在进化上比仅基于序列保守性所预期的更为保守。因此,即使序列差异显著但仍具有可检测相似性的蛋白质,也具有共同的结构特性,尤其是整体折叠。
通过同源性建模预测蛋白质结构
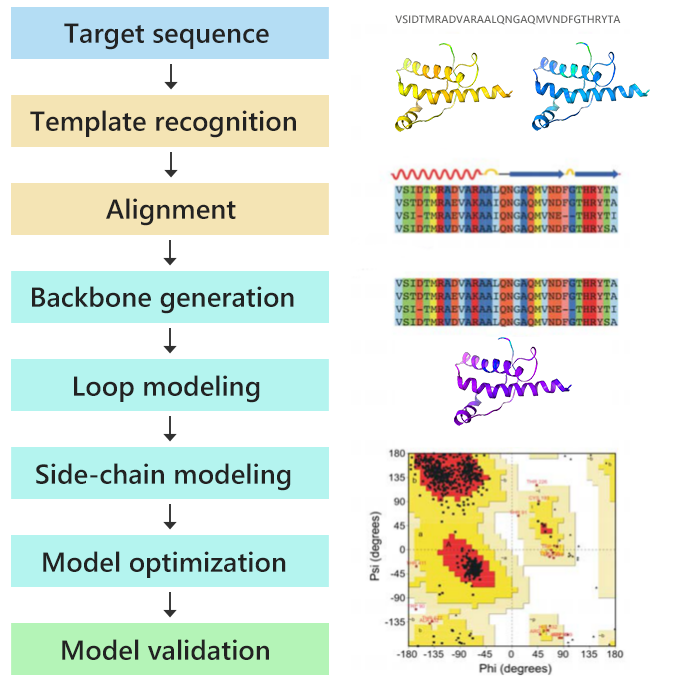
迈博睿利用同源性建模方法帮助客户预测目标蛋白质的三维结构。我们在各种单体和寡聚体蛋白质的建模方面拥有丰富的经验。生成的结构模型均经过质量验证,可用于基因功能注释、分子对接以及指导蛋白质工程和药物设计等进一步的实验工作。
特征
多模板识别与选择通过手动校正实现精确的序列比对
迭代循环建模和侧链优化
多寡聚蛋白质的预测
支持对配体/辅因子结合的诱导契合效应
支持额外的限制
支持非天然氨基酸的掺入
通过多项标准进行质量评估
我们的目标是根据蛋白质序列预测其结构,其准确度可与实验获得的最佳结果相媲美。迈博睿还提供基因组中蛋白质编码区的大规模自动化建模服务。我们根据客户的具体需求定制服务。如需了解更多关于我们同源性建模服务的详细信息,请随时联系我们。